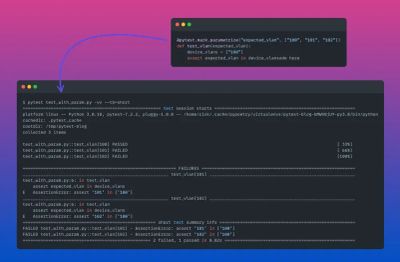
Introduction
Within this guide, we will be diving into the world of parsing and how to create a custom parser from scratch! First, we will look into what parsing is, why it is important in network automation and why we may want to build one from scratch. Then will then dive into how to:
- create a custom parser
- output our parsed data to YAML
- using our parser along with Genie Dq and pyATS.
What is a Parser?
Parsing is a method of translating a blob of unstructured text into a format that can be used programmatically.
For example, most devices have a CLI of some sort, and when you run a command on the CLI, it will return output to the terminal. Though this output is human-readable, it typically cannot be used by a machine. First, we need to translate the CLI output into a structured data format that a machine can work with, e.g. Python Dictionary, JSON, YAML or XML.
Once we have a structured data format, we can then work with the data to achieve our network automation goals.
Looking at the example below, the CLI output (from show bgp summary) has been run and converted into a Python dictionary. For instance, we can run queries against this data to find all the BGP peers who did not have a peer status of Established.
{
"bgp_summary":{
"peers":{
"bgp_neighbor":{
"10.104.34.92":{
"asn":"64400",
"in_q":"0",
"out_q":"0",
"peer_status":"Not_Established",
"pkts_received":"0",
"pkts_Sent":"1",
"remote_asn":"2200",
"state":"Connect"
},
"10.22.1.8":{
"asn":"64400",
"address_family":"VpnIPv4",
"in_q":"0",
"out_q":"0",
"peer_status":"Established",
"pkts_received":"5420893",
"pkts_sent":"426383",
"received":"32",
"remote_asn":"64400",
"sent":"69",
"state":"101"
}
}
}
}
}
What magic did we use here? The most common method of getting structured data like this is via a technique called “screen scraping” or “CLI scraping”. This is where you will use a tool (e.g. pyATS, Scrapli, Netmiko) to collect the data by executing the CLI command and then apply a parser function (script) to convert the CLI output into structured data.
The completed code used within this document can be found on Github at this location:
https://github.com/gwoodwa1/custom_parser
Feel free to clone the repo and follow along with the concepts and examples that are covered.
Ready Baked or DIY?
So far, we have covered the need for parsers but not the how aspect. The first bit of good news is for the common network platforms and operating systems that there are already existing parsers for well-used commands across many vendors and platforms. These come from two primary sources: TextFSM and Cisco Genie (pyATS). I would describe these as “ready baked” parsers since all the work has already been done for you. There is no point in re-inventing the wheel. If one exists already, then why not use it? The development of new parsers is community-led so that everyone can benefit. Personally, I think it’s a wonderful thing to contribute new parsers, which I have done several times using Cisco Genie (pyATS).
However, a common scenario is that if there is no TextFSM or Genie Parser, I am stuck, right? Well, no, you have a few options available at this point. You could use a 3rd party tool like TTP to create a parser, write a parser for TextFSM or Cisco Genie, or you could write your own from scratch.
What helps you make that decision? To write, test and publish a new parser for TextFSM or Cisco Genie is probably an intermediate/advanced level activity. For a novice, it’s off-putting since you will need to understand how you build the templates for the parsers and the associated Regex needed. Once you have built your parser, as we will do here, this learning curve will be reduced, as you will understand what a parser is doing and how it works. We didn’t get to TTP, but that is also an option for creating a parser. I’m a big fan of TTP since the learning curve is not particularly steep, and in some cases, you can be outputting structured data in minutes without any knowledge of Regex. There is an inherent fear of using Regex sometimes, which isn’t always backed up with reality. I would say that having an understanding of Regex is a crucial skill in network automation. For many years we will be working with legacy devices that need parsers that cannot output a structured data format. Okay, so we’ll use TTP, right? In some cases (out of the box), TTP will give you precisely what you want, but equally, it will become complex to achieve the results you’re looking for in some situations. You have no control over how TTP will read a particular set of data, leading to poor results that can be overcome using the macro function in TTP or sometimes just trial and error. Things like spacing have to be addressed and so on, or you don’t get a match. The tricky bit is understanding why a particular piece of output is getting matched or not. TTP abstracts the Regex away from you, but then you’ll often find you still need to use Regex within TTP to get the exact result you’re looking for or at least understand what the built-in pattern matches are.
With this in mind, I think it is better to understand how you could build your parser first. Creating a custom parser from scratch is a great way to learn about the different elements of parsing. You can then build on those skills to contribute to community parsers like TextFSM and Cisco Genie.
We will take a vendor-agnostic approach here because we are interested in the procedure to get structured data and escape from any platform-centric nuances.
High-Level Concepts/Steps
Here are the key learning areas and concepts for writing your own parser that we will cover.
- We need a tool that will help us test our Regex syntax against our output to make sure it’s correct.
- We need to understand capture groups in Regex and specifically named capture groups how they are used and applied to the output.
- We need to understand the correct Regex to capture the correct data but equally not pick up the noise. We need to tailor our Regex not to be too narrow or too strict since we will not end up with the correct data being captured.
- We need to use our Regex pattern matches and extract this into a Python dictionary.
- We need to return the populated Python dictionary to our main script so it can be used for further analysis.
Regex Tooling
There are many Regex guides and cheat sheets, and much of the syntax can be found online. The backslash character \ is used a lot to start Regular Expressions as this indicates a start of a Regex pattern match. Of course, if you have a backslash in your data, then to match it, you would need to provide another backslash to act as an escape character. Any special characters used in Regex need to be escaped if they are part of the text you’re trying to match (which is very seldom). Let’s do a whirlwind tour of Regex and the most common things you will need to know.
| Regex Pattern | Description |
| \d | Matches a single digit/number |
| \d\d | Matches two digits/numbers. |
| \w | Matches a single letter/number regardless of case plus underscore |
| \w\w | Matches two letters/numbers regardless of case plus underscores |
| \w+ | Matches more than one combination of letters/numbers plus underscores |
| \s | Matches a single space character |
| \s\s | Matches two space characters |
| \s+ | Matches more than one space character (greedy capture) until a non-match. (Note: Lowercase "s") |
| \S | Matches any character that is not whitespace |
| \S+ | Matches more than one non-whitespace character (greedy capture) |
| . | Period/Full Stop character is a wildcard that matches any character, except newline (\n) |
| .+ | Greedy capture for any character appearing one or more times |
In terms of tools, we will use regex101 to help formulate the regex patterns. Make sure you select Python in the "flavour" as per below.
The command (shown below) I will write a parser for is somewhat niche and is not (at the time of writing) available within the community list of parsers via Genie or TextFSM.
R1# show service-routing database
Service-Routing Database
Service ID (Service:Subservice:Instance) Trust Domain Owner Size
------------------------------------------------ --------- ------ ----- -----
100:1:31000000-0000-0000-0000-520000000000 Connected * 1 392
100:2:31000000-0000-0000-0000-520000000000 Connected * 1 1074
101:2:675952D8-B2F9-38A8-AE06-8CE5000160D1 Connected 1 2 565
101:2:933EF17C-54BA-5610-0325-B23200019D2E Connected 1 4 387
The fields which need capturing are: Service, SubService, Instance, Trust, Domain, Owner and Size.
The output from this command has a structure and format which is standard, and we can capture all these fields within a single line of Regex by building up each capture group one at a time. If you haven't used capture groups before, do not worry. We will cover them further shortly.
We will need multiple capture groups to grab each part of the data. Starting with the first set of digits separated by a colon.
Defining Capture Groups
Capture groups define a named group that can be referenced for processing of the data.
In our example, the first field we need to capture is Service which is a collection of digits followed by a colon. Of course, we are interested in the digits which form the service and not the colon character.
Syntax of Capture Groups
The syntax of a named capture group is shown below:
(?P<capture group name>regex to capture)
In our example, we give an arbitrary capture group name, e.g. service would make sense since it relates to the data we are capturing. We next need to define the regex after the capture group name.
(?P<service>\d+)
We then need to add in the separator the colon, as this will designate where we need to start our next capture group, SubService.
(?P<service>\d+):(?P<sub_service>\d+):
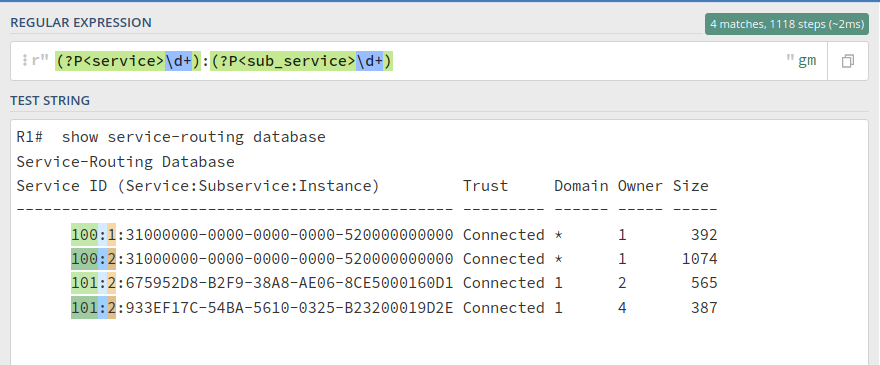
We can also see the matches which are being made against each group:
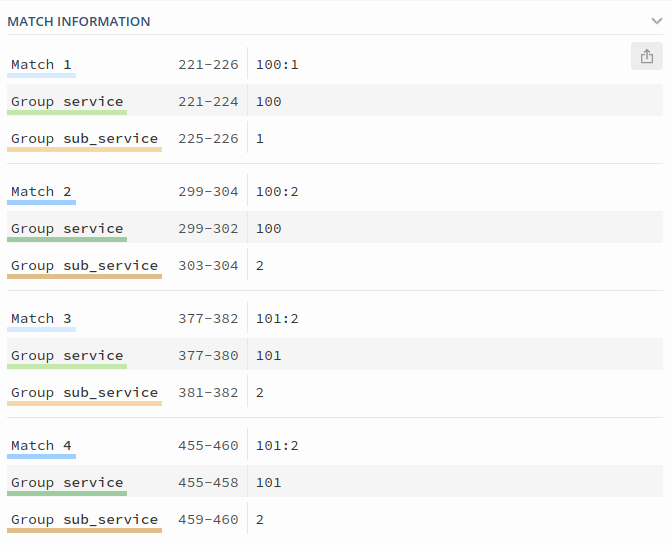
(?P<service>\d+):(?P<sub_service>\d+):(?P<instance>\S+)
The next capture group is our Trust field which is delineated by a single space from the previous Instance field. I would suggest you could use \s here, but if, for whatever reason, the Instance field ends up being fewer characters (we have to make an assumption here), then \s+ could be better to account for a future corner case. Therefore I will use the below:
\s+(?P<trust>\w+)
The full path (so far) looks like this:
(?P<service>\d+):(?P<sub_service>\d+):(?P<instance>\S+)\s+(?P<trust>\w+)
We now need to capture the Domain field, which contains an asterisk., Therefore, \S is the best way of matching either the number or asterisk in that field. Again we use the plus sign to cover any cases where there may be one or more characters within this field.
(?P<domain>\S+)
The next two fields are both numbers/digits so we’ll capture them at the same time and account for the spacing:
\s+(?P<owner>\d+)\s+(?P<size>\d+)
That completes the full line as follows:
(?P<service>\d+):(?P<sub_service>\d+):(?P<instance>\S+)\s+(?P<trust>\w+)\s+(?P<domain>\S+)\s+(?P<owner>\d+)\s+(?P<size>\d+)
We can then wrap the Python re.compile around our pattern, and we will assign a variable later in our code.
re.compile(r"(?P<service>\d+):(?P<sub_service>\d+):(?P<instance>\S+)\s+(?P<trust>\w+)\s+(?P<domain>\S+)\s+(?P<owner>\d+)\s+(?P<size>\d+)")
Defining our Parser Module
All we need to do now is define a module that can be called with the parser and return a dictionary. In addition we will also write a YAML file copy so we could import it back in later.
The first thing is to create a template that can be used for multiple parsers, and for that, my preference would be to use a class and substantiate each parser as a function under the class. In this case, show_serv_database will be called as the function to output the Python dictionary and YAML file.
We only need the built-in Python regular expression and YAML modules; hence we import those first.
We need the output=None set as a default since we will pass the output string from the command into this module and process it as a Python dictionary. We create an empty dictionary called output_dict to pass back to the main script that will be calling this function.
TIP! It’s good practice to include a copy of the output line which the pattern is matching as a comment. This just helps you remember the pattern you were trying to match if you come back to this many weeks later and forget.
We will use an index number as our sorting key because we cannot guarantee that any individual values like service_id or sub_service will be unique. In some cases, it is possible to just select a particular field, for example, an IP address or Interface for the sorting key. Still, you must know the permutations which could lead to duplicates/overlapping keys. If there is any chance of overlapping keys, then it’s best to use an index with an incrementing number, e.g. 1,2,3,4,5 etc. and then each entry is contained within one of those index numbers. However, some disadvantages are that index values themselves are meaningless, and the ordering can change. This could be a problem if you compare two datasets that were obtained at different times.
An alternative method is to make up a unique sorting key by combining values together. By that, I mean concatenating the service_id with the sub_service and the instance then; this may be enough to create a unique sorting key. However, the premise is to guarantee a unique key and if you can’t be sure then it’s best to stick with an index approach.
If you wanted to do that instead then I have included the code snippet, which is a string concatenation with underscores as the separators.
This will create a unique sorting key like this for each entry:
>>> index = group["service"] + "_" + group["sub_service"] + "_" + group["instance"]
>>> print(index)
_101_2_933EF17C-54BA-5610-0325-B23200019D2E_
In this case, I will use an index value as my sorting key as I can’t guarantee the uniqueness.
examples/custom_parser.py
import re
import yaml
class custom_parsers:
def show_serv_database(self, output=None, device_name=None, yaml_out=None):
result = output
self.output_dict = {}
# 100:1:31000000-0000-0000-0000-520000000000 Connected * 1 392
pat1 = re.compile(
r"(?P<service>\d+):(?P<sub_service>\d+):(?P<instance>\S+)\s+(?P<trust>\w+)\s+(?P<domain>\S+)\s+(?P<owner>\d+)\s+(?P<size>\d+)"
)
index = 0
The first thing we will need to do (example below) is to use the splitlines() method within a for loop to iterate over each line of our raw text output. We use the strip() method to remove any leading or trailing spaces on each line. It’s good to do this, or otherwise, your Regex pattern has to ensure the correct number of spaces are in place on each line which is tricky and can lead to matches not being made.
...
for line in result.splitlines():
if line:
line = line.strip()
else:
continue
Next (shown below), we need to feed in each line against the Regex match pattern stored in our pat1 variable. We store this in a variable called match_pattern. If there is a match, then we will trigger the proceeding if statement. Since the index will be our unique key, we have to increment the index by one each time to create index 1,2,3,4,5 etc.
index +=1 is the shorthand way of doing index = index+1 though the latter is easier to comprehend when reviewing code.
A groupdict() expression returns a dictionary containing all the named subgroups of the match. We then apply our regex object match_pattern to groupdict(), which will give us a dictionary of matches using the capture group names and assign this to a variable called group.
...
match_pattern = pat1.match(line)
if match_pattern:
index +=1
group = match_pattern.groupdict()
Entering the Python debugger (for more information on pdb, please see here), we can confirm that the contents of the variable group is a dictionary, and we have captured all the data for the first line that we matched.
(Pdb) dir()
['device_name', 'group', 'index', 'line', 'match_pattern', 'output', 'pat1', 'pdb', 'result', 'self', 'yaml_out']
(Pdb) type(group)
<class 'dict'>
(Pdb) group
{'service': '100', 'sub_service': '1', 'instance': '31000000-0000-0000-0000-520000000000', 'trust': 'Connected', 'domain': '*', 'owner': '1', 'size': '392'}
The next thing we need to do is add this captured content into a new dictionary and think about the ways our parser could break. The first thing to consider is a schema.
What could happen if I always expect an integer for a certain field, but in fact, I end up with a string? Why do I need to declare something as an integer, float or string? Does it matter one way or the other?
To answer these questions, we must look beyond simply capturing the data and what we will do with the resulting data.
(Pdb) group['service']
'100'
(Pdb) group['sub_service']
'1'
If we look at our captured data above, we have a service ID that is currently 100 and a sub-service of 1, both of which are strings. Can we guarantee this will always be a number (i.e. integer), or could it be a bunch of letters or characters instead? If we know it will always be a number; maybe we should enforce this value as an integer? Yes, we should as long as we know it will be an integer, but then we need to check its value before adding it via an if statement.
(Pdb) int(group['sub_service'])
1
(Pdb) int(group['service'])
100
We can use isdigit() (shown below) to validate if there is a number there, and if this condition is true, we can safely wrap this into an integer. Notice the response from the Python debugger is True so that this condition will be met. As I mentioned, we will only need this logic to cater for a situation where these fields may not be numbers.
(Pdb) group['service'] and group['service'].isdigit()
True
(Pdb) group['sub_service'] and group['service'].isdigit()
True
Why do we need to be concerned about all this? After the data has been returned, we may want to perform a mathematical calculation on this value (example below), and if we do, then we need an integer and not a string to work with. For example, I may want to check if the values are odds or even numbers and extract those records. I could do that with this simple evaluation which returns False for Evens numbers and True for Odd numbers. If this were returned as a string, then we would not be able to do this without adding code into our main script, which is calling the parser.
(Pdb) int(group['service'])
100
(Pdb) int(group['service']) % 2 != 0
False
(Pdb) int(group['sub_service'])
1
(Pdb) int(group['sub_service']) % 2 != 0
True
(Pdb) (group['sub_service']) % 2 != 0
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: not all arguments converted during string formatting
In summary, it’s a good idea to think about a robust schema and ensure your parser does not break as a result of data that you didn’t expect to collect. Equally, using some sort of enforced schema will prevent incorrect data from being captured.
The next step is to add the results to a dictionary that will be returned to the script, calling the function.
The best way of creating the dictionary is using setdefault() since it will not break if the values are empty. We can also map our main dictionary into a temporary one instead of mapping out every key. We created an empty dictionary called self.output_dict earlier and will now populate it with the returned values.
...
temp_dict = (
self.output_dict.setdefault("hostname", {})
.setdefault(device_name, {})
.setdefault("index", {})
.setdefault(index, {})
)
After running this, we can see temp_dict is empty for now, but self.output_dict has been populated with these values (i.e. the hostname key and the index key). There is a preference to use a hostname key because it clearly defines which host the data came from.
(Pdb) temp_dict
{}
(Pdb) self.output_dict
{'hostname': {'R1': {'index': {1: {}}}}}
Next, we will want to update the dictionary with the service and sub_service keys and values. We will enforce a number for these values, as discussed above, and ensure we have a condition to check for it. We then use the update() method to add those keys and values to the dictionary.
...
if group["service"] and group["service"].isdigit():
temp_dict.update({"service_id": int(group["service"])})
if group["sub_service"] and group["service"].isdigit():
temp_dict.update({"sub_service": int(group["sub_service"])})
Now let’s see what the values are inside the debugger as we update the dictionary. We can see the temp_dict is holding the individual values, and then these are being added to the main dictionary self.output_dict.
(Pdb) temp_dict
{'service_id': 100, 'sub_service': 1}
(Pdb) self.output_dict
{'hostname': {'R1': {'index': {1: {'service_id': 100, 'sub_service': 1}}}}}
The next thing is to update all the remaining keys and values for that particular line into the dictionary.
...
temp_dict.update({"instance": group["instance"]})
temp_dict.update({"trust": group["trust"]})
temp_dict.update({"domain": group["domain"]})
if group["owner"] and group["owner"].isdigit():
temp_dict.update({"owner": int(group["owner"])})
if group["size"] and group["size"].isdigit():
temp_dict.update({"size": int(group["size"])})
We then will go back to the start of the for loop until all the lines have been processed. At which point we will have a dictionary output (shown below), and then all we have to do is return the dictionary to the function which called it.
return self.output_dict
The pretty print output below shows what data has been collected.
(Pdb) pprint.pprint(self.output_dict, width=2)
{'hostname': {'R1': {'index': {1: {'domain': '*',
'instance': '31000000-0000-0000-0000-520000000000',
'owner': 1,
'service_id': 100,
'size': 392,
'sub_service': 1,
'trust': 'Connected'},
2: {'domain': '*',
'instance': '31000000-0000-0000-0000-520000000000',
'owner': 1,
'service_id': 100,
'size': 1074,
'sub_service': 2,
'trust': 'Connected'},
3: {'domain': '1',
'instance': '675952D8-B2F9-38A8-AE06-8CE5000160D1',
'owner': 2,
'service_id': 101,
'size': 565,
'sub_service': 2,
'trust': 'Connected'},
4: {'domain': '1',
'instance': '933EF17C-54BA-5610-0325-B23200019D2E',
'owner': 4,
'service_id': 101,
'size': 387,
'sub_service': 2,
'trust': 'Connected'},
5: {'domain': '1',
'instance': '933EF17C-54BA-5610-0325-B23200019D2E',
'owner': 4,
'service_id': 102,
'size': 387,
'sub_service': 2,
'trust': 'Connected'}}}}}
Outputting to YAML
That’s not the end of the story, though! Commonly, you may want to write this information out to a file where it could be used again later. The easiest way to store the resulting dictionary is in a YAML file. For that purpose, I have a very simple function which, if called, will write a YAML file with the filename passed from the yaml_out variable.
...
def yamlwriter(self, yaml_out=None, input_dict=None):
with open(f"{yaml_out}", "w") as file:
yaml.dump(input_dict, file, allow_unicode=True)
The function is called within the main parser module if it has been specified. The default value is None, which will result in the YAML file function not being called.
def show_serv_database(self, output=None, device_name=None, yaml_out=None)
We check for the existence of a value for yaml_out, and if this condition is met, we call the yaml_writer function to write the file. The input dictionary is the newly created one whilst yaml_out should contain the filename we want to write e.g. yaml_out=f'./show_service_routing_{device_name}.yml.
...
if yaml_out:
custom_parsers().yaml_writer(yaml_out=yaml_out, input_dict=self.output_dict)
The resulting YAML file that is created is shown below:
hostname:
R1:
index:
1:
domain: '*'
instance: 31000000-0000-0000-0000-520000000000
owner: 1
service_id: 100
size: 392
sub_service: '1'
trust: Connected
2:
domain: '*'
instance: 31000000-0000-0000-0000-520000000000
owner: 1
service_id: 100
size: 1074
sub_service: '2'
trust: Connected
3:
domain: '1'
instance: 675952D8-B2F9-38A8-AE06-8CE5000160D1
owner: 2
service_id: 101
size: 565
sub_service: '2'
trust: Connected
4:
domain: '1'
instance: 933EF17C-54BA-5610-0325-B23200019D2E
owner: 4
service_id: 101
size: 387
sub_service: '2'
trust: Connected
If we wanted to load that file back in, we could do something like this:
import yaml
device_name='R1'
with open(f'./show_service_routing_{device_name}.yml') as file:
pre_output = yaml.load(file, Loader=yaml.FullLoader)
I could then re-use that data or compare it against the current dataset.
>>> pre_output
{'hostname': {'R1': {'index': {1: {'domain': '*', 'instance': '31000000-0000-0000-0000-520000000000', 'owner': 1, 'service_id': 100, 'size': 392, 'sub_service': '1', 'trust': 'Connected'}, 2: {'domain': '*', 'instance': '31000000-0000-0000-0000-520000000000', 'owner': 1, 'service_id': 100, 'size': 1074, 'sub_service': '2', 'trust': 'Connected'}, 3: {'domain': '1', 'instance': '675952D8-B2F9-38A8-AE06-8CE5000160D1', 'owner': 2, 'service_id': 101, 'size': 565, 'sub_service': '2', 'trust': 'Connected'}, 4: {'domain': '1', 'instance': '933EF17C-54BA-5610-0325-B23200019D2E', 'owner': 4, 'service_id': 101, 'size': 387, 'sub_service': '2', 'trust': 'Connected'}}}}}
Calling our Parser Module
The only thing remaining is to call our parser module from another script. We would typically collect this real-time from an actual device, but to start with, we will use static data as it provides a great way to make sure your parser works. I always recommend this step with static data since if you do later encounter an issue with the tool you use to collect the output easier to troubleshoot.
examples/run_custom_parser.py
from custom_parser import custom_parsers
import pprint
parser = custom_parsers()
device_name = "R1"
output = """
R1# show service-routing database
Service-Routing Database
Service ID (Service:Subservice:Instance) Trust Domain Owner Size
------------------------------------------------ --------- ------ ----- -----
100:1:31000000-0000-0000-0000-520000000000 Connected * 1 392
100:2:31000000-0000-0000-0000-520000000000 Connected * 1 1074
101:2:675952D8-B2F9-38A8-AE06-8CE5000160D1 Connected 1 2 565
101:2:933EF17C-54BA-5610-0325-B23200019D2E Connected 1 4 387
102:2:933EF17C-54BA-5610-0325-B23200019D2E Connected 1 4 387
"""
result = parser.show_serv_database(
device_name=device_name,
output=output,
yaml_out=f"outputs/show_service_routing_{device_name}.yml",
)
pprint.pprint(result, width=20)
The first thing we do (shown below) is import our new parser and make the functions available. We also use pprint, also known as pretty print, to see the results on the terminal.
from customparser import CustomParsers
import pprint
Next, we create an instance of our CustomParsers object. Like so:
parser = CustomParsers()
The variable output is a multiline string (hence the triple quotes) representing the data we have collected from the device. I have statically assigned a variable for the hostname, but this could be a string coming from a for loop if we are iterating over many devices.
We call the module and specify the values we want to pass to the module. The resulting dictionary will be installed in a variable called result. We then print the result.
result = parser.show_serv_database(
device_name=device_name,
output=output,
yaml_out=f"outputs/show_service_routing_{device_name}.yml",
)
pprint.pprint(result, width=20)
Genie Dq Example
Here is an example (shown below) of a query we could do with this dataset. The path of least resistance is to use Dq, a module found in Cisco pyATS (more info on Dq can be found here) that helps with parsing through structured data. Here we find all the entries which do not have a "Connected" status and create a new dictionary called failed_dict to contain these entries. Because my sorting key is an index number that is essentially an arbitrary number, this alone is not enough. I want to collect all the keys and values residing there, like the service_id and sub_service. Plus, it would be handy to write out the failed entries to a YAML file. If I check the resulting dictionary is not empty, it will tell me if I have picked up any failures. Furthermore, I could also cookie cut this process for other failures or conditions to create additional YAML files identifying where issues have been found. These could then be added to a ZIP or RAR and emailed to the Operations team via an additional Bash script, as part of a scheduled task.
from genie.utils import Dq
import yaml
import pprint
device_name = "R1"
with open(f"outputs/show_service_routing_{device_name}.yml") as file:
output = yaml.load(file, Loader=yaml.FullLoader)
failed_entries = (
Dq(output)
.not_contains("Connected", level=-1)
.contains("trust", level=-1)
.reconstruct()
)
pprint.pprint(failed_entries)
if failed_entries:
with open(f"outputs/FAILED_show_service_{device_name}.yml", "w") as file:
yaml.dump(failed_entries, file, allow_unicode=True)
Extracting and querying Python datasets is a separate topic in its own right. We’re more focused on collecting the data at this stage, but hopefully, this is a teaser of the kind of things you could think about doing.
Collecting the Device Output
Differences in Datasets
What's the difference between using static data and a tool like pyATS, Netmiko, or Napalm to collect the data? On the face of it, you wouldn’t think there is a difference, and both are interchangeable. However, there are differences (not with every tool), but you certainly need to be aware of the considerations. For example, when using pyATS to collect the output, it will include the \r, which is a carriage return. Since these characters will be part of the line, it can cause issues with the Regex matching. For that reason, it is vital to doctor the output coming from pyATS (as per below) to avoid this issue. In this case, we remove the \r characters from the output altogether.
output = output.replace('\r\n','\n')
If your parser works when using static data but not when using live output from the device, then make a very careful comparison and look for the differences. Sometimes there are minor differences in the way the command displays on a virtual versus physical device. I would recommend exploring using mock devices with data collected from production nodes since this is the most robust way of testing your parser before deployment. At a fundamental level, I would use the Python debugger and look for those subtle differences between the static data and the actual output.
Collection with pyATS
I am using a simple pyATS script to connect to the device and collect the data using our custom-built parser. My preference is to decouple the output collection from the post logic since it is easier to scale. In this case, pyATS can be replaced by any other tool to collect the data, and the logic I use afterwards to query the data then doesn’t need to change.
examples/collect_custom_parser.py
from custom_parser import custom_parsers
from genie.conf import Genie
import pprint
parser = custom_parsers()
testbed = Genie.init("../testbeds/genie_testbed.yml")
for device in testbed.devices:
# Connect to the device
print(f" Connecting to Device: {device}")
testbed.devices[device].connect()
# Fetch raw output
output = testbed.devices[device].execute("show service-routing database")
output = output.replace("\r\n", "\n")
# Return parsed output
result = parser.show_serv_database(
device_name=device,
output=output,
yaml_out=f"outputs/show_service_routing_{device}.yml",
)
pprint.pprint(result, width=2)
Final Thought
Using a Regex based "screen scraping" approach is not desirable, but it is often necessary. There are still many legacy devices without an API or structured data format, making Regex your only choice.
I would like to thank you for reading, and I hope this has been useful in learning more about the world of network automation parsing.
Sponsored by