In this post, we will answer the question, "What is Schema Validation?".
But before we do, let's set the stage by discussing a fundamental aspect of network automation: Data. And when I say data, I mean "good" data!
Data
Data is required for everything from generating network configurations using Jinja templating to declaring the intended state used when testing that the network is running as expected.
Good Data
But this data needs to be "good". E.g: The VLAN IDs we supply must be that of, well, a VLAN ID, i.e., an integer, between 1 and 4094. The IP addresses we supply must comply with the format of what an IP address actually is.
Bad Data
What will happen is that this data is not "good" and, in fact, "bad". We may end up with a rendered configuration that is not valid. Think switchport trunk allowed vlan add 200, 300, 400, 5000. Python scripts that fail due to incorrect data types and tests testing the wrong values, e.g.: assert 1500 == "1500".
Therefore, we need a way to check that our data is of a specific type/format (aka good!) ...
What is Schema Validation?
Schema validation is the process of validating that the format, structure and type of our data aligns with a set of rules.
Schema validation involves two key components: the schema itself and the data to be validated. The schema acts as a blueprint, outlining the expected format, structure, and data type. It can specify constraints like data types (e.g., integers, strings), value ranges, required fields, and acceptable formats.
When data is subjected to schema validation, it is checked against these predefined rules. If the data aligns perfectly with the schema, it passes the validation process. However, any deviation from the schema in format, type, or structure triggers an error.
How to Perform Schema Validation
When it comes to network automation, you will typically find your data comes from 2 sources - a source of truth (such as NetBox) or flat files (version-controlled YAML or JSON). Or even a mix of both.
Source of Truth
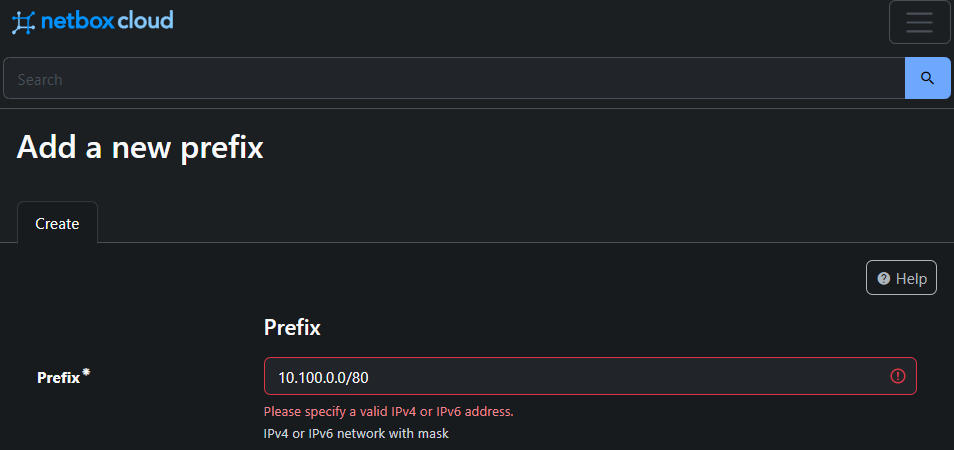
If we take a popular Source of Truth, such as NetBox, schema validation is actually baked in. Thanks to the underlying database already having its schema defined for the various fields. You may have already seen this if you tried to enter an IP value in that is not valid.
Flat Files
When it comes to validating the schema of data within flat files, there are various tools, such as Pydantic, Cerberus and JSON Schema.
One of the most popular tools out there is JSON Schema (previous tech session here). With JSON Schema, you provide the schema and then apply this to your data (also referred to as a document).
Below is a quick example of JSON Schema:
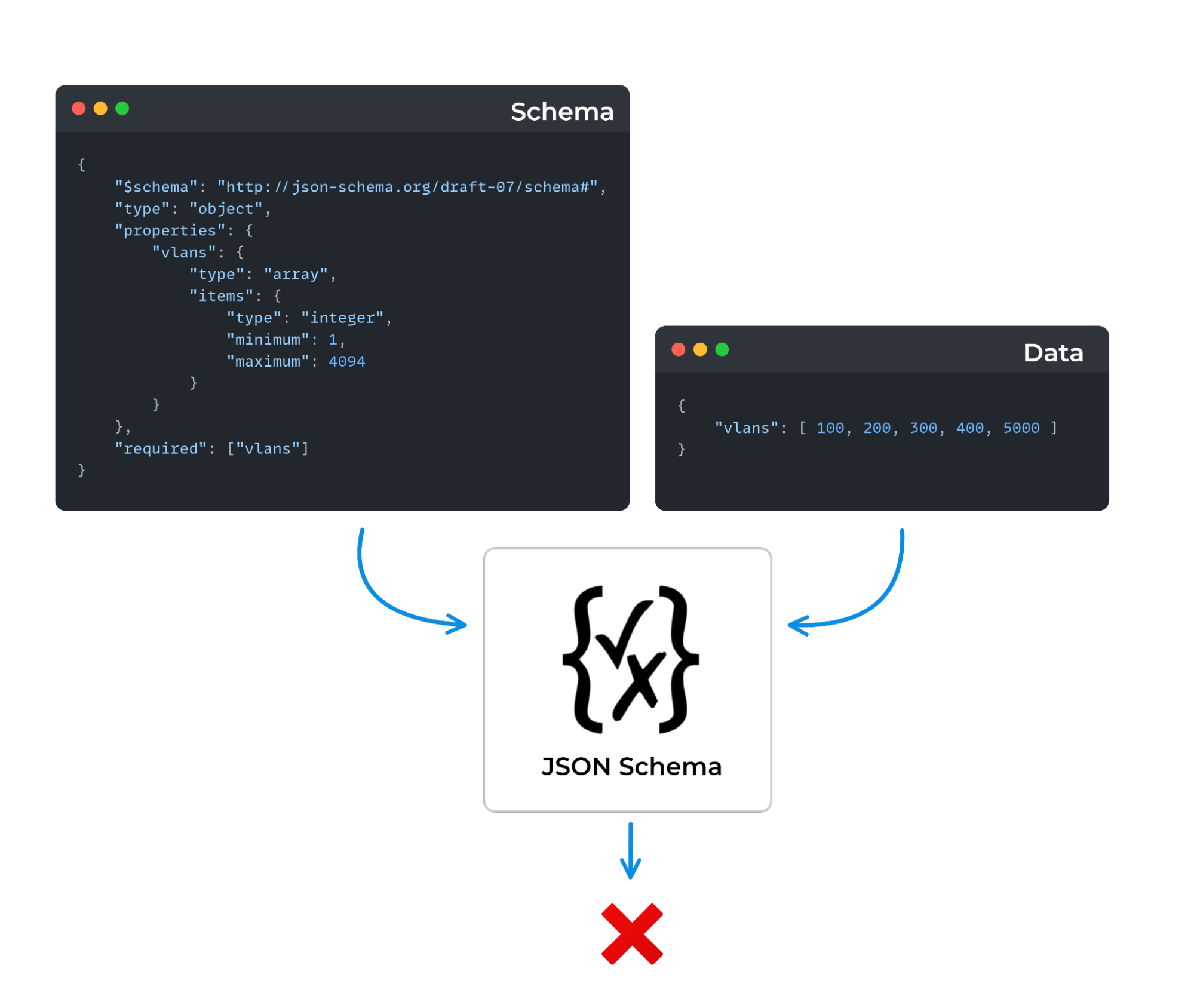
That wraps up this post. Remember, schema validation is vital in building reliable, production-grade systems. And essential for ensuring error-free and predictable outcomes in your network automation workflows.
Until next time...
Sponsored by