
In this lesson, we will cover:
- What is Scrapli?
- Scrapli’s common use cases.
- Scrapli’s key features.
What is Scrapli?
Scrapli is a Python library developed by Carl Montanari that simplifies the process of connecting to devices (typically network-based), via Telnet or SSH for the purpose of sending commands and screen scraping.
Scrapli takes away the heavy lifting and the boilerplate code typically required when interacting with devices (i.e. connection setups, prompt handling and dealing with string handling within the response). Scrapli is also highly flexible. Thanks to various transport plugins and async/sync support, you can customise it as needed for your given use case.
Here are some of Scrapli’s use cases:
- Configuration backups – automate the collection of the running configuration on a scheduled basis via Netconf.
- Configuration rollout – push out a new configuration to several devices across the network.
- Configuration validation – run show commands across your network and get the response back as structured output so you can work with it programmatically.
Scrapli Features
Let’s dive into the various Scrapli features. But before we do, here is an overview of Scrapli to help you visualise the features.
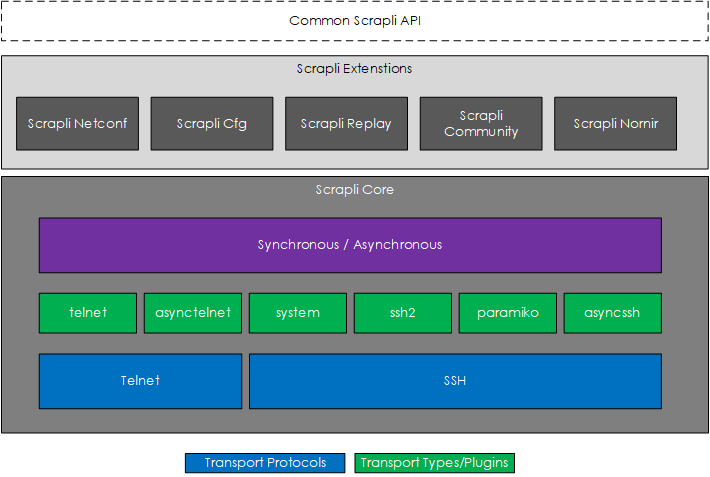
Flexible Transport
Scrapli is extremely flexible when it comes to the underlying transport as it allows you to select the transport protocol and transport type (the underlying libraries/drivers) used to connect to the device. The Scrapli transport options are:
- Transport protocol – Telnet or SSH.
- Transport types – plugins (SSH)
system(OpenSSH)ssh2paramikoasyncssh
- Transport types – plugins (Telnet)
telnetasynctelnet
Note: In later lessons we will cover the pros and cons of each plugin type.
Sync/Async Support
For both the Telnet and SSH transport protocols, Scrapli provides asynchronous and synchronous support.
What does this mean?
Synchronous support is the Python we all know and love – our code waits for something to finish before moving on. In the world of networking, we send a command and wait for the response from the device. If we have 100 devices, this would take a while, so we look to use multi-processing (multiple CPU cores) or multi-threading to perform a level of concurrency and parallelism by running our synchronous code on multiple cores or threads.
In the world of asynchronous Python (AsyncIO), we use the asyncio library to perform concurrency without needing to use multi-processing or multi-threading. asyncio concurrently runs your code on a single thread, which is achieved via the asynchronous scheduling of your functions. The key takeaway here is that the overhead, compared to multi-threading, is far less. This topic is covered in much more detail in the AsyncIO lesson later on in this course.
 Rick Donato
Rick Donato
Scrapli Extensions
Scrapli, also known as Scrapli Core, provides several extensions that offer additional functionality.
- Scrapli Cfg – provides additional functionality for working configurations such as loading candidate configurations, creating diffs of the current and candidate configurations, and committing and rolling back configurations.
- Scrapli Netconf – provides support (async and sync-based) for NETCONF over SSH.
- Scrapli Replay - a collection of tools to help test Scrapli programs. This includes the ability to capture interactions from devices and replay them, along with a Pytest plugin to help with testing against the captured interactions.
- Scrapli Nornir – a plugin that allows you to use Scrapli directly within the Nornir Python Framework.
- Scrapli Community – a repository for additional platforms outside of the core platforms supported by Scrapli. For further details see here.
Multi-Vendor Support
Scrapli (Core) provides support to the following platforms:
- Arista EOS.
- Cisco NX-OS.
- Cisco IOS-XE.
- Cisco IOS-XR.
- Juniper JunOS.
Note: The supported platforms are the same core platforms that NAPALM supports.
Parsing Support
Scrapli supports the parsing libraries Genie, TTP and TextFSM. This direct integration results in the parsing of your raw/unstructured output into structured data so that you can work with it programmatically.